Trong những năm gần đây, chúng ta đã chứng kiến sự bùng nổ của Trí tuệ Nhân tạo (AI), đặc biệt là trong lĩnh vực Học sâu (Deep Learning). Các mô hình ngày càng lớn hơn, phức tạp hơn, và đòi hỏi khả năng xử lý thông tin khổng lồ. Để đáp ứng nhu cầu này, một kiến trúc đột phá có tên Mixture-of-Experts (MoE) đã nổi lên, hứa hẹn một cuộc cách mạng trong cách chúng ta xây dựng và huấn luyện các mô hình AI.
Vậy, Mixture-of-Experts (MoE) là gì và tại sao nó lại được coi là chìa khóa mở ra kỷ nguyên mới của AI? Hãy cùng học viện MP ACADEMY tìm hiểu chi tiết về công nghệ đầy tiềm năng này.
Giới thiệu về Mixture-of-Experts (MoE)
Về cơ bản, Mixture-of-Experts (MoE) là một kiến trúc mạng nơ-ron (neural network) trong đó thay vì một mô hình duy nhất xử lý tất cả các loại đầu vào, chúng ta có một tập hợp các “chuyên gia” (experts). Mỗi chuyên gia này là một mạng nơ-ron nhỏ hơn, được thiết kế để xử lý hiệu quả một loại dữ liệu hoặc nhiệm vụ cụ thể.
Ý tưởng chính là:
- Không phải mọi dữ liệu đều giống nhau: Một hình ảnh chó cần được xử lý khác với một văn bản pháp lý, và việc dự đoán thời tiết khác với việc chẩn đoán bệnh.
- Chia để trị: Thay vì bắt một mô hình khổng lồ học mọi thứ, MoE chia nhỏ nhiệm vụ cho các chuyên gia riêng biệt.
Mô hình MoE được hình thành từ hai thành phần chính:
- Chuyên gia (Experts): Là các mạng nơ-ron con độc lập, mỗi mạng có khả năng chuyên biệt trong việc xử lý một khía cạnh hoặc một loại dữ liệu nhất định.
- Cổng (Gate/Router): Đây là một mạng nơ-ron nhỏ khác có nhiệm vụ học cách “điều hướng” đầu vào đến (các) chuyên gia phù hợp nhất.
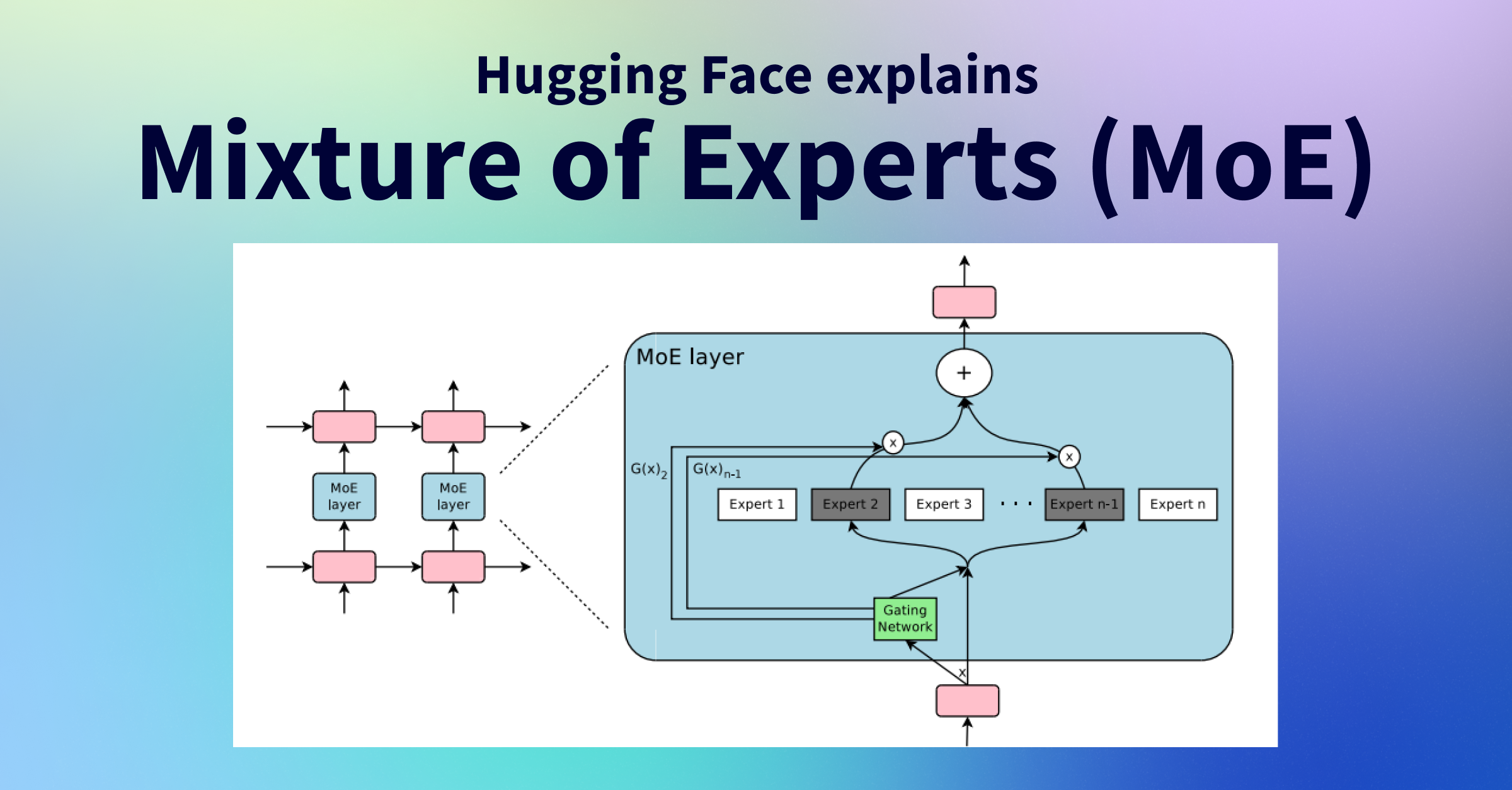
Cách thức hoạt động của kiến trúc MoE
Hãy tưởng tượng một hệ thống MoE giống như một nhóm cố vấn chuyên nghiệp:
- Đầu vào đến: Khi có một dữ liệu đầu vào (ví dụ: một câu hỏi, một hình ảnh), nó sẽ đi qua Cổng (Gate).
- Cổng quyết định: Dựa trên đặc điểm của dữ liệu đầu vào, Cổng sẽ đánh giá và quyết định nên “gửi” dữ liệu này đến một hoặc một vài Chuyên gia (Experts) nào trong nhóm. Cổng sẽ gán “trọng số” cho từng chuyên gia, cho biết mức độ liên quan của chuyên gia đó với đầu vào hiện tại.
- Chuyên gia xử lý: Dữ liệu đầu vào sau đó được truyền đến các chuyên gia được chọn. Mỗi chuyên gia sẽ xử lý phần công việc của mình.
- Kết hợp kết quả: Cuối cùng, kết quả từ các chuyên gia được chọn sẽ được tổng hợp lại (thường bằng cách nhân với trọng số mà Cổng đã gán) để tạo ra kết quả đầu ra cuối cùng của toàn bộ mô hình MoE.
Ví dụ, trong một mô hình ngôn ngữ lớn sử dụng MoE, nếu bạn đưa vào một câu hỏi về vật lý, Cổng có thể nhận ra và chỉ kích hoạt các chuyên gia được đào tạo chuyên sâu về vật lý, thay vì bắt toàn bộ mô hình phải xử lý tất cả các lĩnh vực.
Ưu điểm nổi bật của MoE
Kiến trúc MoE mang lại nhiều lợi ích vượt trội, đặc biệt quan trọng đối với các mô hình AI quy mô lớn:
- Tăng hiệu suất đáng kể: Đây là lợi ích lớn nhất. MoE cho phép mô hình đạt được hiệu suất cao hơn với cùng số lượng tham số tính toán (FLOPs) so với các mô hình dày đặc (dense models) truyền thống. Điều này có nghĩa là chúng ta có thể huấn luyện các mô hình lớn hơn, mạnh mẽ hơn mà không cần tăng chi phí tính toán một cách tuyến tính.
- Hiệu quả về tính toán: Mặc dù tổng số tham số của một mô hình MoE có thể rất lớn, nhưng tại một thời điểm, chỉ một phần nhỏ các chuyên gia được kích hoạt. Điều này giúp giảm đáng kể chi phí tính toán cho mỗi lần suy luận (inference) hoặc huấn luyện (training step).
- Khả năng mở rộng (Scalability): Rất dễ dàng để thêm nhiều chuyên gia vào mô hình MoE mà không làm tăng quá nhiều chi phí tính toán cho mỗi lần chạy, giúp mô hình dễ dàng mở rộng quy mô.
- Khả năng học chuyên biệt: Mỗi chuyên gia có thể học và trở nên rất giỏi trong một nhiệm vụ hoặc một loại dữ liệu cụ thể, dẫn đến khả năng học tốt hơn và tổng quát hóa tốt hơn cho toàn bộ mô hình.
- Xử lý dữ liệu đa dạng: MoE đặc biệt hiệu quả khi mô hình cần xử lý nhiều loại dữ liệu hoặc nhiệm vụ khác nhau, ví dụ như trong các mô hình đa phương thức (multi-modal models) xử lý cả văn bản, hình ảnh, âm thanh.
Nhược điểm và thách thức của MoE
Bên cạnh những ưu điểm vượt trội, MoE cũng đối mặt với một số nhược điểm và thách thức cần được giải quyết:
- Tăng cường yêu cầu bộ nhớ: Mặc dù hiệu quả về tính toán, tổng số tham số của mô hình MoE rất lớn. Điều này đòi hỏi lượng bộ nhớ (RAM/VRAM) khổng lồ để lưu trữ tất cả các chuyên gia, gây khó khăn cho việc triển khai trên các phần cứng thông thường. Các Software Engineer và Developer cần các kỹ thuật tối ưu hóa bộ nhớ khi làm việc với MoE.
- Phức tạp trong huấn luyện: Việc huấn luyện mô hình MoE có thể phức tạp hơn so với các mô hình truyền thống, đặc biệt là việc cân bằng tải (load balancing) giữa các chuyên gia để đảm bảo tất cả các chuyên gia đều được sử dụng hiệu quả và không có chuyên gia nào bị bỏ rơi.
- Độ trễ (Latency) tiềm ẩn: Mặc dù hiệu quả tính toán, việc điều hướng qua Cổng và sau đó tập hợp kết quả từ các chuyên gia có thể gây ra độ trễ nhất định, đặc biệt nếu các chuyên gia được đặt trên các thiết bị hoặc máy chủ khác nhau. Điều này cần được các Solution Architect cân nhắc kỹ lưỡng.
- Rủi ro “kẹt chuyên gia”: Một chuyên gia có thể trở nên quá “nổi tiếng” và được Cổng chọn quá thường xuyên, khiến các chuyên gia khác ít được huấn luyện và kém hiệu quả. Các kỹ thuật như “auxiliary loss” được sử dụng để giảm thiểu vấn đề này.
- Yêu cầu hạ tầng đặc biệt: Để triển khai và huấn luyện các mô hình MoE quy mô lớn, cần có hạ tầng tính toán phân tán mạnh mẽ, như các cụm GPU lớn hoặc TPU.
Ứng dụng thực tế và tương lai của MoE
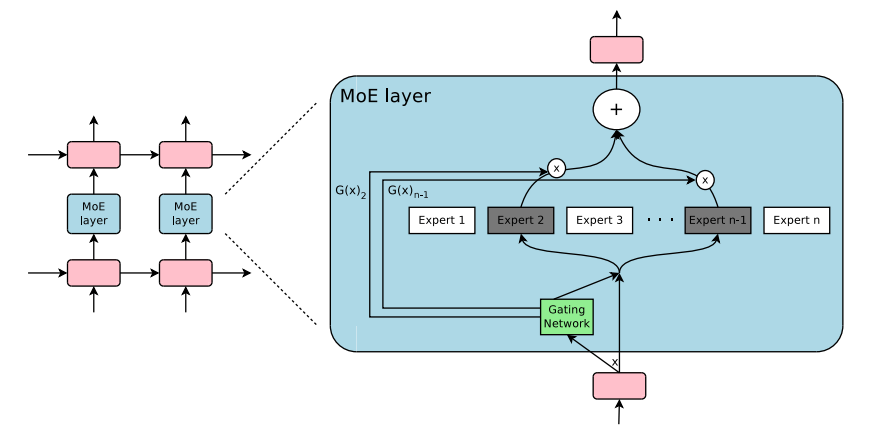
Kiến trúc MoE đã và đang được ứng dụng mạnh mẽ trong nhiều lĩnh vực AI, đặc biệt là với sự ra đời của các mô hình ngôn ngữ lớn (LLMs):
- Mô hình ngôn ngữ lớn (LLMs): Google Brain đã đi tiên phong trong việc sử dụng MoE với các mô hình như GShard, Switch Transformer và gần đây là Gemini. Kiến trúc này giúp các LLMs đạt được kích thước khổng lồ với hiệu suất ấn tượng mà vẫn duy trì khả năng truy vấn hiệu quả. Các Data Scientist và AI Engineer đang tích cực khai thác tiềm năng này.
- Xử lý ngôn ngữ tự nhiên (NLP): MoE có thể cải thiện hiệu suất trong các tác vụ như dịch máy, tóm tắt văn bản, trả lời câu hỏi bằng cách cho phép các chuyên gia tập trung vào các khía cạnh ngữ pháp, ngữ nghĩa, hoặc các ngôn ngữ cụ thể.
- Thị giác máy tính (Computer Vision): Trong một số trường hợp, MoE có thể được dùng để xử lý các loại hình ảnh khác nhau hoặc các vùng khác nhau của một hình ảnh, giúp nhận diện vật thể hoặc phân tích cảnh quan hiệu quả hơn.
- Hệ thống đề xuất (Recommendation Systems): Các chuyên gia có thể học hỏi từ sở thích của các nhóm người dùng khác nhau hoặc các loại sản phẩm khác nhau, giúp hệ thống đưa ra đề xuất chính xác hơn.
Trong tương lai, kiến trúc MoE được kỳ vọng sẽ tiếp tục là một hướng nghiên cứu và phát triển trọng tâm, mở ra cánh cửa cho các mô hình AI ngày càng thông minh, hiệu quả và có khả năng giải quyết các vấn đề phức tạp mà trước đây không thể.
Kết Luận
Mixture-of-Experts (MoE) không chỉ là một khái niệm học thuật mà là một bước tiến đáng kể trong kiến trúc mạng nơ-ron, giải quyết bài toán về khả năng mở rộng và hiệu quả tính toán cho các mô hình AI khổng lồ. Việc nắm bắt và hiểu rõ về MoE là điều cần thiết cho bất kỳ ai muốn làm việc trong lĩnh vực Trí tuệ Nhân tạo và Học sâu, từ Developer xây dựng mô hình, Data Scientist phân tích dữ liệu, đến Solution Architect thiết kế hệ thống AI quy mô lớn.